
신청
"빨리 가려면 혼자가고, 멀리가려면 함께가라!"
올해부터 스프링 공부를 본격적으로 시작 했었고, 스프링이라는 거대한 생태계에 관심이 생겼다.
지금, 진행하는 프로젝트에도 2023년 가을에 나온 Spring AI 를 사용하기 시작했고 이 생태계가 꾸준한 기술발전에 더 함께하고 싶어졌다.
마침, 애플리케이션 서버 개발자들과 함께 가치있는 기술에 관한 정보과 경험을 '공유'하는 "스프링 캠프 2024" 참여하기로 했다.
SpringCamp2024
SpringCamp2024
springcamp.ksug.org
입장
행사는 SETEC 컨벤션 홀에서 진행되었다

들어가자 마자 접수를 하고 팔찌, 키캡, 스티커, 물을 받고 입장했다.
메인홀에는 카카오뱅크랑 현대 자동차에서 나와서 상담을 하면 굿즈를 받을 수 있는 부스도 존재했었다.
진행은 두개의 트랙이 동시에 진행되며 하나를 선택해서 참여 할 수 있었다.
| Track 1 | ||
|---|---|---|
| 12:00 ~ 13:00 | 접수 / 등록 | |
| 13:00 ~ 13:45 | Tidy First | 안영회 |
| 14:00 ~ 14:45 | Spring AI : LLM에도 봄이 찾아오다. | 황민호 |
| 14:45 ~ 15:15 | Coffee Break | |
| 15:15 ~ 16:00 | 왜 나는 테스트를 작성하기 싫을까? | 조성아 |
| 16:15 ~ 17:00 | 실전! MSA 개발 가이드 | 김용욱 |
| 17:15 ~ 18:00 | 구해줘 홈즈! 은행에서 3천만 트래픽의 홈 서비스 새로 만들기 |
이영규 |
| Track 2 | ||
|---|---|---|
| 12:00 ~ 13:00 | 접수 / 등록 | |
| 13:00 ~ 13:45 | 동시성의 미래 - 코루틴의 버츄얼 스레드 | 이상훈 |
| 14:00 ~ 14:45 | Spring Coroutine In Action | 최진영 |
| 14:45 ~ 15:15 | Coffee Break | |
| 15:15 ~ 16:00 | 스프링 R2DBC 연동 기능을 활용한 작은 코틀린 SQL DSL 개발기 |
오현석 |
| 16:15 ~ 17:00 | 데이터를 스케치 하기 | 황영 |
| 17:15 ~ 18:00 | AutoParams를 사용한 Spring Boot 응용프로그램 테스트 |
이규원 |
나는 처음부터 끝까지 Track 1 에 참여했다.
Tidy First
켄트 벡의 Tidy First? - 번역 저자 "안영회"님께서 세션 발표를 해주셨다.

전체적으로 느낀점을 한 문장으로 정리하면 아래와 같다.
"나와 협업 잘하기"
코드 정리법에 대한 이야기를 해주셨다.
코드 정리에 대한 4가지 선택지 제안해 주셨다.
- 이미 잘 되고 있는데, 굳이 깔끔하게 할 필요는 없다
- 나중에 하기
- 코드정리는 미래에 내가 빠르게 정리하기 위함
- 지금 당장의 버그를 수정하는것도 필요핟
- 동작 변경 직후에 정리하기
- 코드정리가 한시간이 넘어가면 코드정리가 아니다
- 지금해야 빨리 할 수 있다 느끼는거라면 지금 하는게 좋을 수 있다
- 코드 정리 후 동작 변경 (이게 가장 추천하는 최상의 방법)
- 기분이 좋아야 생산성이 좋아진다
- 깨끗한 책상에서 일하는게 기분이 좋다
가장 이상적인 방법으로 코드 정리 후 동작 변경을 하는 방법을 제안해 주셨다.
평소 나의 코딩 습관을 들여다 볼 수 있었다.
평소 나는 "동작 변경 직후 정리하기" or "나중에 하기" 방식으로 진행 하고 있었다.
음,,, 이런 방법론이 왜 필한가...? 라는 생각을 할 때쯤 이론에 대한 이야기를 함께 해주셨다.
그 중 가장 와 닿았던 이야기는 생존 부등식에 관한 이야기이다.
생존 부등식?
가치 > 가격 > 비용

이게 기업 경영의 기본이라고 한다
이 내용을 개발자에게 적용 시키면 아래와 같다
코드의 가치 > 고객 만족도 > 비용(시간)
고객 입장에서는 기능이 동작하기만 하면 되는것이고
코드의 가치는 유지보수의 용이성을 포함한 내용인 것 같다.
이 중에서도 개인인 내가 유념해야 할 부분이 "비용" 과 "코드의 가치"를 산정하는 일인 것 같다.

코드를 잘 정리할수록 코드의 가치가 높아져, 다음에 코드를 작성하는 비용이 줄어든다.
이때, 코드를 정리를 하는 타이밍이 중요한 것같다.
생각해보면, 기능 코드를 작성 한 직후 코드를 정리하는 것과 나중에 몰아서 코드를 정리하는것은 비용의 차이가 크다.
보통
기능 코드 직후 < 나중에
이렇게 비용의 크기가 달라진다.
앞으로, 이후 코드를 정리할때의 비용도 생각하며 지금 어디까지 정리해두는게 더 유리할지 판단하는 연습이 필요할 것 같다.
Spring AI : LLM에도 봄이 찾아오다.
제일 흥미롭게 들었던 강연이었다.
최근 진행하고 있는 "시험지 연구소" 프로젝트에도 GPT와 같은 LLM을 도입할 일이 있었고, 사용할 방법을 고민하던 중 "Spring AI" 를 사용하기 시작했었기 때문이다.
Spring AI

Spring AI는 python, javascript 진영에 존재하는 LLM 프레임워크에 영감 받아 만들어졌다고 한다.
최근에 이런 LLM을 사용하는 개발이 많이 진행되며 앞으로도 큰 개발 흐름 중 하나로 자리잡을것을 생각해서 작년에 Spring 정식 프로젝트가 되었다고 한다.
개인적으로 GPT나 Clova Studio api를 사용하면서, 이를 잘 사용하기 위한 고민을 많이 했었다.
이런 API를 프로젝트에 잘 통합하는게 백엔드 개발자로서 꼭 필요한 능력이라 생각 들지만, 이를 정말 잘 사용하기 위해서는 프롬프트 또한 잘 해야한다는 점이다.
강연 중에서도, 중간중간 "이런 부분은 프롬프트 엔지니어들이 할 영역이다" 라고 소개해주시며 프롬프트 엔지니어의 역할을 구분해 주셨다.
또, 프롬프트 엔지니어 방법론이 있다며 짧게 넘어간 부분이 있었다.
덕분에 백엔드 개발자가 어디를 더 집중으로 학습해야할지 알 수 있었다.
RAG

RAG란 오픈북 시험 같은거라고 한다.
필요한 정보를 추가적으로 제공하며 그 정보를 기반으로 답을 할 수 있도록 하는 방법이다.

RAG를 활용하면 더 비용이 저렴한 모델을 더 효율적으로 사용할 수 있다.
나도 이런 기능이 필요함을 느꼈었다.
"시험지 연구소" 프로젝트를 진행하며 달성해야할 목적이 있었다
- 사용자의 강의 자료를 기반으로 시험문제를 만들어야 한다
- 응답을 파싱할 수 있도록 원하는 형식으로 시험문제가 생성 되어야 한다
- 비용
특히 "1. 강의 자료를 기반으로 시험문제를 만들어야 한다" 를 해결하며 LLM이 사용자의 강의 자료를 모른다는 점에서 부터 고민이 시작되었다.
나 또한 예시에 나오는 RAG 방식으로 문제를 해결했었다
아래 내용을 참고해서 시험문제를 만들어줘
{강의 자료}
이번 강연을 계기로 벡터 데이터베이스 도입을 통해서 이를 더 최적화 할 수 있음을 알 수 있었고, 이를 적용해 보려 한다
"2. 원하는 형식으로 시험문제가 생성"
이 부분은 프롬프트 엔지니어링 영역이라고 생각할 수 있지만 제시해주신 방법, 사실 나도 하고있던 방법으로 계속해서 최적화 해보려고 한다
- 프롬프트 과정
- 아이다어
- 구체화
- 다양한 실험
- 평가
"3. 비용"
또, Spring AI 프레임워크의 장점으로 구현체를 쉽게 바꿀 수 있다는 점을 활용해서 로컬에서 "Ollama" 사용하기도 하며, 언제든 더 저렴하고 성능 좋은 모델이 사용가능하면 적용할 수 있도록 Spring AI 프레임워크를 최대한 활용해보려 한다.
가드레일
최근 카카오에서도 적용했던 어체 바꾸기의 문제
아무리 심도있게 테스트를 해 보아도 현실적으로 문제가 생길 수 있다.
이에대해 연사님께서 현실적인 해결법으로 앞뒤로 가드레일을 하는 방법을 제시해 주셨다.
입력을 필터링, 결과를 필터링 하는 방법이다.
나 또한 "시험지 연구소" 프로젝트를 진행하며 LLM이 원하는 답변이 제대로 나왔는지 필터링 하는 과정을 거쳤으며 현실적인 문제를 해결해 보이려 했다.
이 부분을 더 잘 검증할 수 있는 방법 또한 고민해 보아야겠다.
왜 나는 테스트를 작성하기 싫을까?

Fixture Monkey maintainer 님께서 연사님과 테스트 코드의 연대기 같은 이야기를 들려주셨다.
GitHub - naver/fixture-monkey: Let Fixture Monkey generate test instances including edge cases automatically
Let Fixture Monkey generate test instances including edge cases automatically - naver/fixture-monkey
github.com
테스트 레벨이 강제로 오르는 환경에 계셨다고한다.
테스트 하기 어렵지만 테스트가 정말 필요한 도메인인 결제 부분을 개발 하셨다고 한다.
테스트는 좋은 영향만 할 것 같지만 테스트가 정말 많이 생기기 시작하면 테스트가 깨지기 시작한다.
간헐적으로 테스트가 깨진다
-> 테스트가 작성하기 싫어짐
이때도 개발하는데 비용이야기가 중요하게 작용한다.
- 낮아진 테스트 작성 비용, 넓어진 테스트 범위
- 주문서 특성상 모든 코드를 테스트해야한다는 생각
- 테스트 유지보수 비용을 생각못함
테스트의 이득과 비용이 뭐지?
테스트를 작성하기 싫은 이유
비용 > 이득
작성 비용, 유지보수 비용 > 확장 비용
시스템이 커지면 커질수록 테스트가 없으면 확장을 할 수 없겠다는 고민이 든다.
나 또한 Git Challenge 프로젝트를 진행하며 6주안에 프로젝트를 완성해야한다는 목적아래 "코드 정리"와 "테스트 코드"를 많이 못하였다.
6주의 프로젝트 발표 이후 이를 개선하려고 하였으나 역시나 쉽게 코드를 변경할 엄두가 나지 않았다.
테스트 코드가 없어서 내가 하는 행위가 어디까지 영향을 미칠 지 확인하기 어려웠다.
또, 개인적으로는 테스트 하기 어려운 어쩌면 테스트하기 어렵게 코드가 작성 되지 않았나 걱정도 된다.
마침, 연사님께서 테스트 코드가 하나도 없는 프로젝트에 어떻게 적용하는게 좋을지 의견을 몇가지 주셨다.
- 정말 필요한 도메인 부분을 우선적으로 적용하기
- 구조를 개선할 수 있다면 개선하기
나의 경우 두가지 다 적용해야 겠다는 생각을 했다.
지금 이 Git Challenge 프로젝트를 개선할 아이디어를 계속해서 생각해내고 있지만, 이 확장 비용이 두려워서 적용을 못하고 있다. 이를 해결 할 수 있도록 "Tidy First" 나와 먼저 잘 협업하고 내가 나의 코드를 고치고 싶게 만들 필요가 있다고 느껴졌다.
실전! MSA 개발 가이드
아직 나는 MSA에 대해 공부해 본적이 없어 어렵게 느껴질까 걱정 했었다.
하지만, MSA개발의 고민이 평소 내가 하는 고민과 크게 다르지 않음을 알 수 있었다.
오히려 MSA가 적용되지 않은 내 프로젝트에도 적용할 아이디어들이 떠올랐다.

모델링
특히 데이터 복제는 데이터 관리에 새로운 시선을 주었다.
데이터의 특성을 파악하자
자주 참조, 변경 빈도
필요한 속성만 복사하기 -> 내가 사용하는 속성만 필요한 부분만 조회
공통된것을 수정하는 부분은 따로 있으니까, 바뀌면 전파하고
공통 부분을 복사해둔다

둘 다 저장하면 단방향 동기화로 상담 내용을 고객쪽으로 옮김
뭔가, 실제로 데이터를 조회하는 관점에서 모델링이 설계되었다고 생각들었다.
이런 생각은 못하고 있던 것 같다.
당연히도 고객 정보면 고객 테이블에
상담 관련 내용은 상담 테이블에 넣는게 모델링할때 자연 스럽게 느껴지지만, 이런 실 상황에서 데이터 위치를 바꾸게되면 두번 조회할 내용을 한번 조회로 해결 할 수 있게된다.
성능 개선의 방법은 쿼리 튜닝이나, 네트워크 개선, 캐시 도입과 같은 방법만 생각하고 있었는데 어떤 구조 변경으로도 성능 개선이 가능할 수 있다는 시선이 생겼다.
조회
조회에 대해서도 평소 많이 하던 고민이 정리되었다.
여러번 조회할걸 한번 일괄조회로
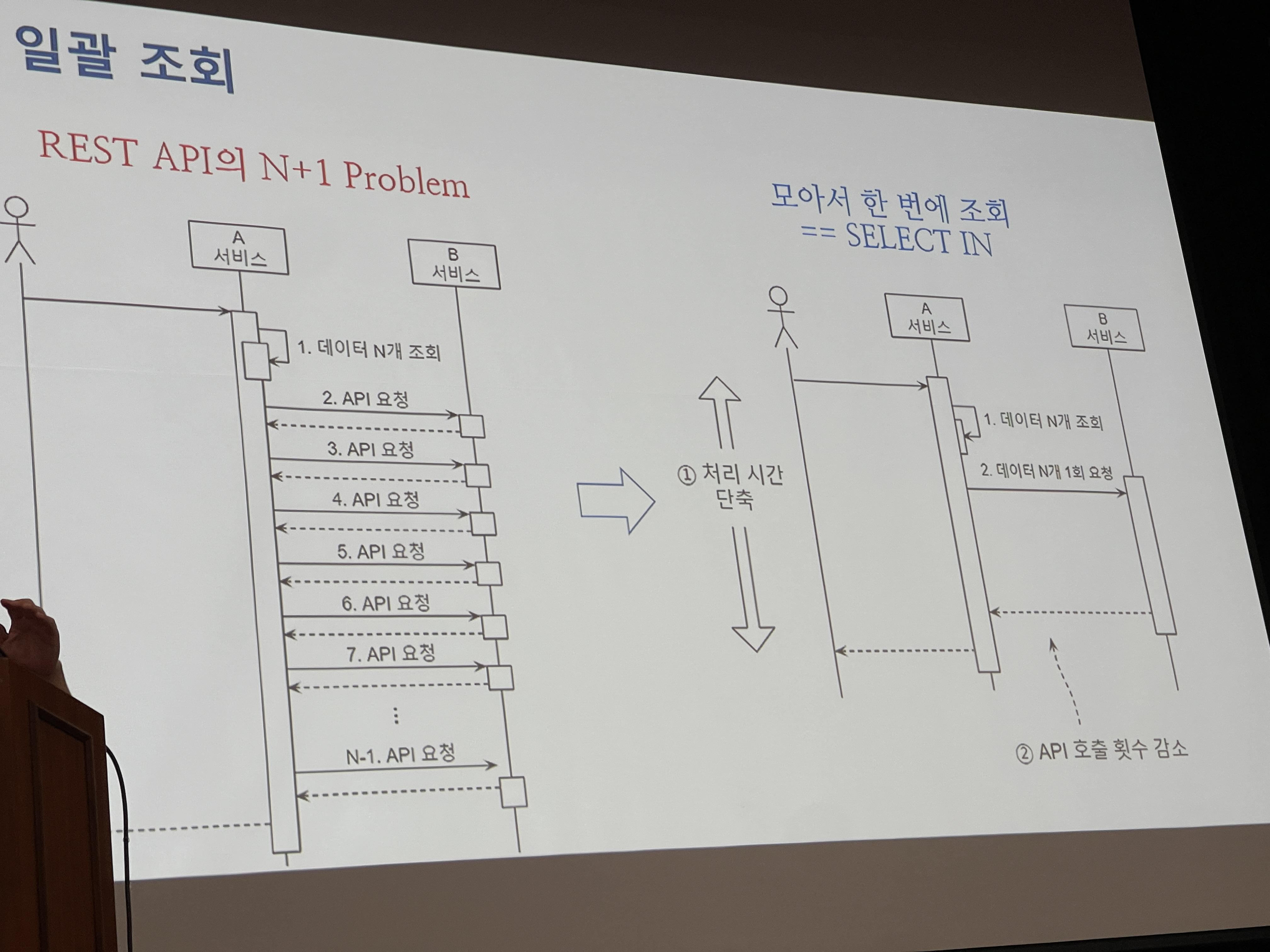
병령 조회도 대부분 안티패턴이 될 수 있으므로 꼭 필요한 경우에만 사용하도록 하자

구해줘 홈즈! 은행에서 3천만 트래픽의 홈 서비스 새로 만들기
주된 내용은 레거시 결제 서비스를 새롭게 개발한 이야기가 주된 내용이었다.
나에게도 큰 인사이트가 되었다.
지금 나는 nest.js로 되어있는 Git Challenge 프로젝트 백엔드를 Spring으로 이사를 해볼 계획을 하고 있다.
nest.js를 이전 서비스, spring을 신규 서비스로 도입하고 싶다.
같은 목적의 서비스를 두개의 프레임워크로 개발해보며 두 언어와 프레임워크를 비교하며 내용을 학습해보려 한다.
역시나 순탄하지 않을 것이다. 이런 걱정 아래에 이 강연의 개발일기는 좋은 개발 인사이트가 되었다.
A / B 비교 테스트
보통 테스트하면 테스트코드가 떠오르기 쉽지만, 실제 요청이 왔을때 A, B 모두 실행해보고 그 결과를 비교하며 새로운 서비스가 잘 동작하는지 테스트 하는것이다.
현재 Git Challenge 프로젝트는 반년 넘게 문제없이 잘 운영되고 있어서 이를 적용해서 새로운 Spring 서비스가 잘 동작하는지 테스트 할 수 있을것이다.
연사님께서도 이런 테스트를 통해서 여러 차이를 찾았다고 하셨다.
하지만, 시간 차이와 같은 다른 외부적인 요인으로 결과의 차이가 생기는 경우가 있어 이를 조심해야 한다고 하셨다.
로드 밸런싱
두가지 버전의 서비스를 사용하며, 언제든지 동적으로 A 서비스와 B 서비스가 받는 요청의 양을 변경 할 수 있도록 하였다고 한다. 이는 언제든 새로 만든 서비스가 문제가 생겼을때 기존에 잘 동작하던 A 서비스가 응답하도록 변경 가능하게 한다는것을 의미한다.
동시에 B 서비스가 실패할 경우 자동으로 A 서비스가 실패한 요청을 위임해서 처리할 수 있도록 하셨다고 했다.
나도 이를 적용해 보고 싶지만, 나에게 걱정은 두개의 서비스가 동시에 동작해야 하는거라 데이터 베이스같은것을 어떻게 분리해두는게 좋을지(?) 걱정도 드는 한편, 두개의 서비스가 동시에 동작하려면 서버 인스턴스도 두개라 비용적인 측면도 같이 걱정된다.
결론
역시나 여러 비용이 제일 관건인듯 하다
앞으로도 나와 잘 협업하며 나만의 비용을 측정할 수 있는 경험을 길러가야 할 것 같다.
많은 경험과 인사이트 또 많은것을 배울 수 있는 행사였다.
특히, 굿즈로 주신 키캡 너무 마음에든다 ㅎㅎ